Case study: a real 1 GB ETL on the staging volume¶
A worked, measured end-to-end pipeline: generate ~1 GB, process it with DuckDB,
and load the result into an external Postgres — all on leoflow lite running real
pods on a single-node k3d cluster (a "pseudo-cluster" on a laptop). Every number
below was measured on that setup.
What it exercises
Per-run staging volume (ADR 0022) · DuckDB out-of-core processing · cross-pod data sharing · an external load through a managed Connection (ADR 0019/0021) · the volume lifecycle (success vs. failure) · clear + re-run with staged-data reuse (ADR 0020) · per-deployment version tracing.
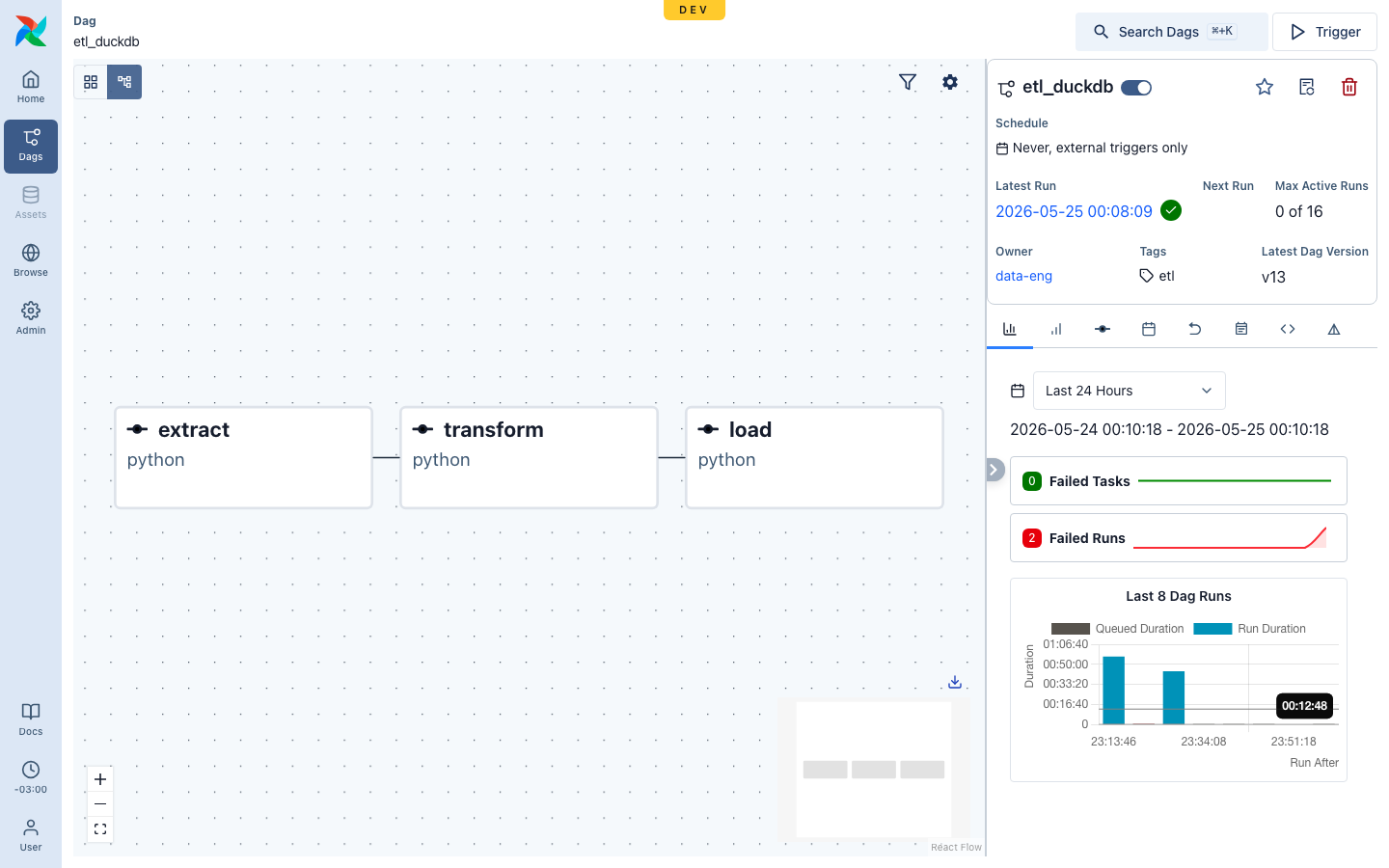
The pipeline¶
Three tasks, each in its own pod, sharing one /staging volume for the run. XCom
carries only small paths/metadata; the GBs live on /staging.
flowchart LR
E["extract (pod)"] --> T["transform (pod)"] --> L["load (pod)"]
D[("/staging<br/>one PVC per run")]
E -->|writes raw| D
T -->|writes agg| D
D -->|reads agg| L
L -->|50 rows| PG[("external Postgres<br/>managed Connection")]import os, time
from airflow.sdk import DAG, task
STAGING = os.environ.get("LEOFLOW_STAGING_DIR", "/staging")
ROWS = 70_000_000 # ~1.1 GB as Parquet
@task
def extract() -> dict:
import duckdb # heavy import INSIDE the task (see gotcha)
raw = f"{STAGING}/raw.parquet"
duckdb.connect().execute(f"""
COPY (SELECT i AS id, 'cat_' || (i % 50) AS category,
(random()*1000)::DECIMAL(10,2) AS amount
FROM range({ROWS}) t(i)) TO '{raw}' (FORMAT parquet)""")
return {"raw": raw}
@task
def transform(meta: dict) -> dict:
import duckdb
agg = f"{STAGING}/agg.parquet"
duckdb.connect().execute(f"""
COPY (SELECT category, COUNT(*) n, SUM(amount) revenue
FROM read_parquet('{meta["raw"]}') GROUP BY category)
TO '{agg}' (FORMAT parquet)""")
return {"agg": agg}
@task
def load(meta: dict) -> None:
import duckdb, psycopg2
rows = duckdb.connect().execute(
f"SELECT category, n, revenue FROM read_parquet('{meta['agg']}')").fetchall()
# Managed Connection injected by the agent (AIRFLOW_CONN_<ID>), never in the pod spec.
dsn = os.environ["AIRFLOW_CONN_ETL_TARGET"]
with psycopg2.connect(dsn) as conn:
cur = conn.cursor()
cur.executemany("INSERT INTO category_revenue VALUES (%s,%s,%s)", rows)
with DAG("etl_duckdb", schedule=None, catchup=False, tags=["etl"]):
load(transform(extract()))
Measured results¶
Single-node k3d on a 10-core laptop, real pods, --executor=k8s:
| Task | Work | DuckDB time | Pod time |
|---|---|---|---|
| extract | 70,000,000 rows → raw.parquet (1,056 MB) |
7.7 s | 8.9 s |
| transform | 70M rows → 50 groups → agg.parquet |
0.3 s | 1.1 s |
| load | agg → 50 rows into external Postgres | — | 0.8 s |
| whole run | including pod scheduling | ~21–25 s |
The run detail makes the timing concrete — ~22 s for ~1 GB end to end on a laptop pseudo-cluster, with per-task durations:
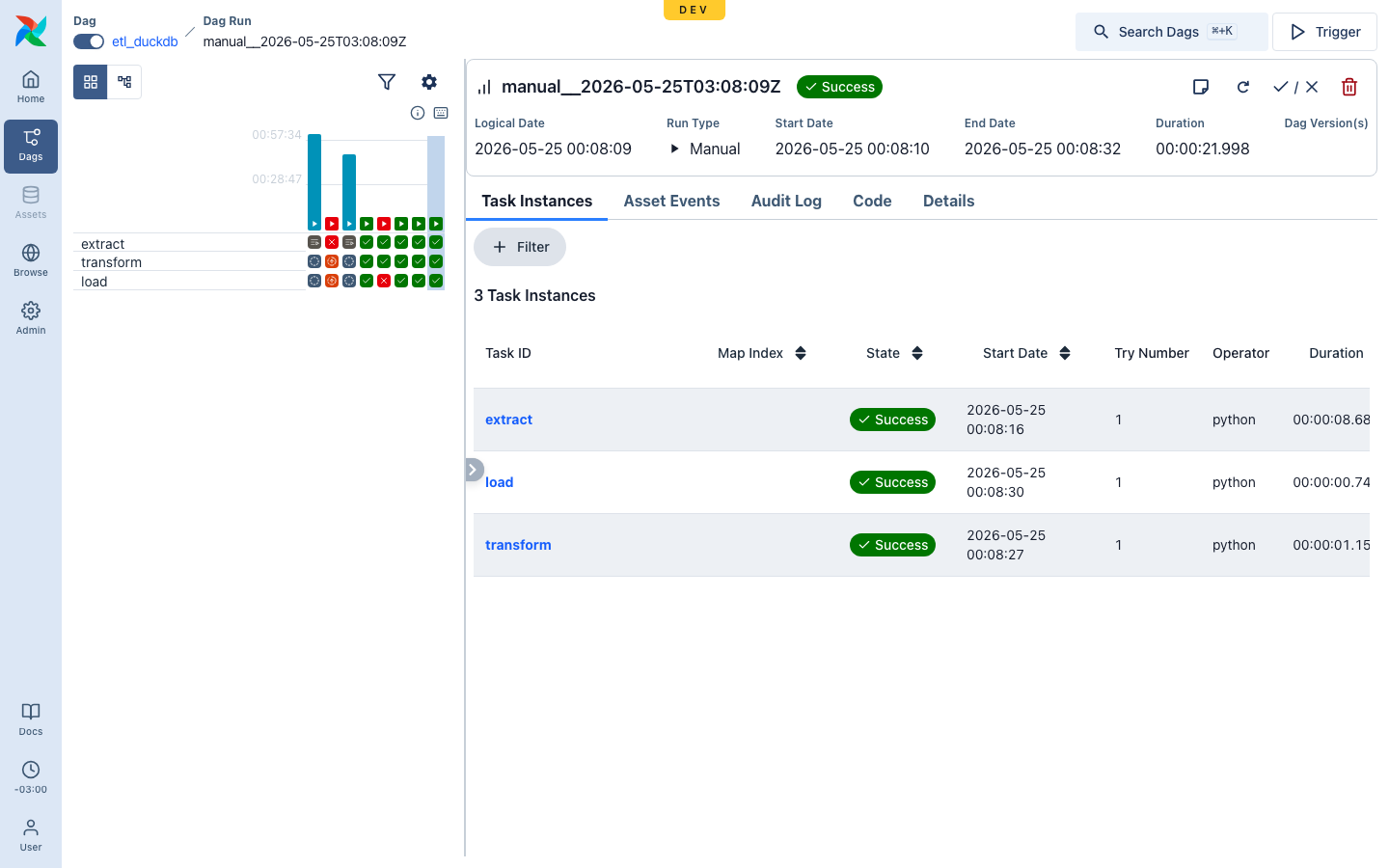
DuckDB is vectorized, multi-threaded, and out-of-core, so ~1 GB of Parquet is
written in seconds and aggregated in a fraction of a second — within a
memory-modest pod. The 1.1 GB lives on /staging, written by extract and read
by transform and load — three pods, one disk, verified physically:
$ ls -la /staging # mounted from the run's PVC
-rw-r--r-- 1000 1,152,463,115 raw.parquet # ~1.1 GB
-rw-r--r-- 1000 1,940 agg.parquet
-rw-r--r-- 1000 2,800 output.csv
The staging volume lifecycle (ADR 0022)¶
The per-run PVC is tracked in the metadatabase (staging_volumes: state,
created_at, deleted_at, delete_reason) — auditable: when and why each
disk was reclaimed.
| Run outcome | Volume |
|---|---|
| Success | deleted immediately at run end — delete_reason = run_succeeded |
| Failure | kept for 24 h after terminal (ttl_expired after) — so a fix-and-re-run reuses the upstream data |
| Run row gone | reclaimed once older than the TTL — orphaned |
A GC sweep that cannot resolve a volume's run never deletes a fresh volume — only ones older than the TTL — so an active run's pods are never stranded.
Clear + re-run reuses staged data (ADR 0020)¶
When load failed (external Postgres down), the run was failed so its volume
was kept. After fixing the external dependency, clearing only load :
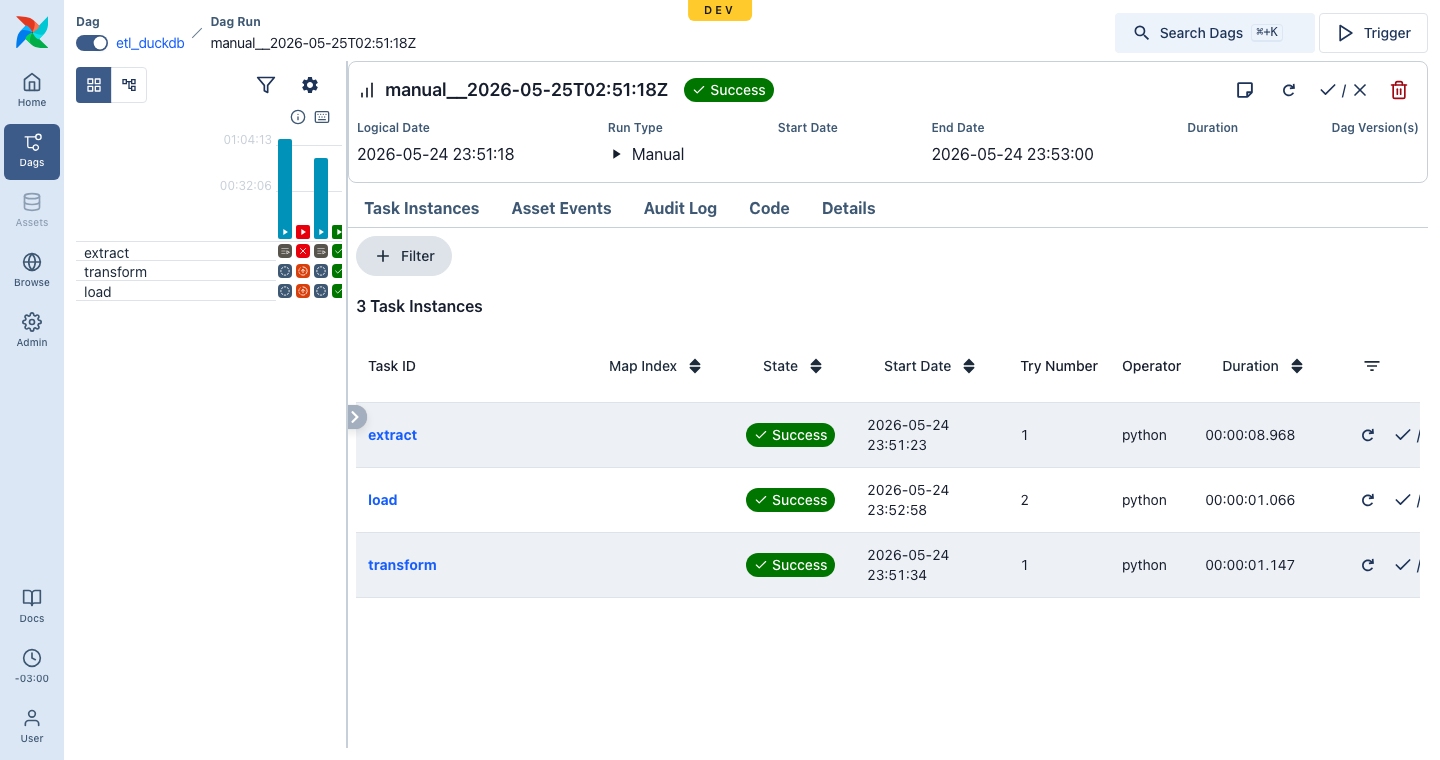
extractandtransformstayedsuccess(not re-run),loadre-ran alone, re-attached the same PVC and read the existingagg.parquet(no 1 GB regeneration), and loaded successfully.
The task instances make it visible — load is on try 2, extract and
transform stayed on try 1 (never re-executed):
clear also re-binds the run to the DAG's current version (the single
mutability rule): a re-run after a code/yaml fix picks up the newest image — the
last hot-reload in dev, the last deploy in prod.
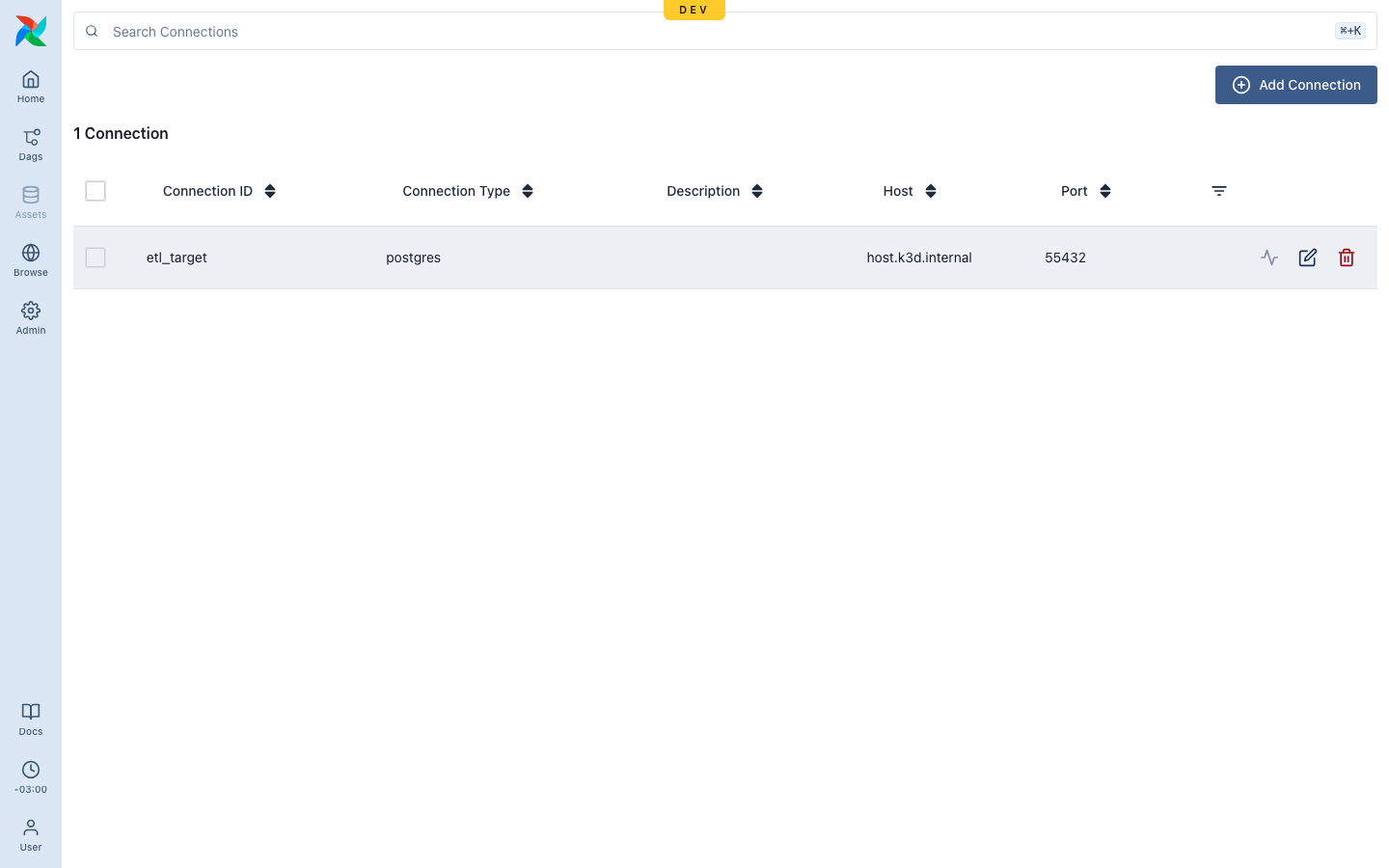
The external load uses a managed Connection¶
The load target is a Leoflow Connection (etl_target), created in
Admin → Connections — encrypted at rest (ADR 0019) and injected into the pod as
AIRFLOW_CONN_ETL_TARGET over an authenticated gRPC pull (ADR 0021), so the
secret never appears in the pod spec. The task log confirms it:
load: connecting via managed Connection etl_target
load: loaded 50 rows into EXTERNAL postgres warehouse.category_revenue
The Connection is managed in the UI (encrypted; the password is never returned):
Each run is traceable to the exact deployment that produced it: the
dag_versions entry carries a deployment label (git describe in prod,
dev-<timestamp> in dev), surfaced as bundle_version on the version API.
Gotcha: import heavy deps inside the task¶
import duckdb / import psycopg2 go inside the task functions, not at module
top level. The DAG parser imports the module to extract structure and does not
have the task image's dependencies — a top-level heavy import fails parsing (and
lights the Import Errors banner).